第2回:機械学習の基礎と主要アルゴリズム
1. 機械学習とは?
機械学習(Machine Learning)は、データからパターンを学び、それをもとに将来のデータを予測したり、分類したりする技術です。従来のプログラムではなく、データから「学習」するため、複雑な処理が可能です。
機械学習の種類
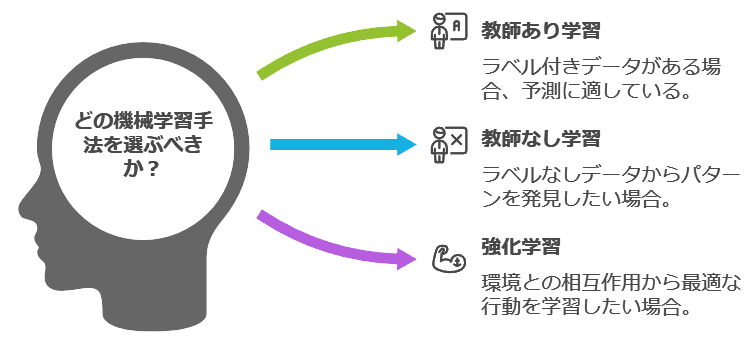
1. 教師あり学習(Supervised Learning)
何をする? コンピューターに「正解」がわかるデータをたくさん見せて、「次もこれと同じように判断してね」と教えます。
例
- 回帰:過去のデータから未来を予測します。たとえば、「来月の気温はどれくらい?」など。
- 分類:写真を見せて「これは猫、これは犬」と教えると、コンピューターも新しい写真で猫と犬を見分けられるようになります。
2. 教師なし学習(Unsupervised Learning)
何をする? 今度は、正解がないデータを見せて、コンピューターにデータの中の似ているところや、面白いパターンを見つけさせます。
例
- クラスタリング:たとえば「このグループはよく似ている」といったように、似ているもの同士でグループを作ります。お店が「このタイプの客はよく買い物をする」と分けるのに役立ちます。
- 次元削減:たくさんのデータを分かりやすく整理して、「このデータはまとめるとこういう特徴があるよ」と教えます。
3. 強化学習(Reinforcement Learning)
何をする? コンピューターが「何をしたらうまくいくか」を、試行錯誤しながら覚える方法です。良い行動をすると「報酬」をもらえ、間違えた行動をするとペナルティがもらえます。こうして、だんだん最適な行動を学びます。
例
- 自動運転:AIが運転して「どう動いたら事故を避けられるか」「どうしたらスムーズに走れるか」を学びます。
- ゲームAI:ゲームで勝つためにAIが自分の動きを工夫して、勝つ方法を学んでいきます。
2. 教師あり学習のアルゴリズム
回帰分析
回帰分析は、数値データを予測するための手法です。特に線形回帰は、連続変数の予測に用いられ、関係を直線で近似します。
分類問題
分類は、データをクラスに分けるタスクで、以下のような手法が用いられます。
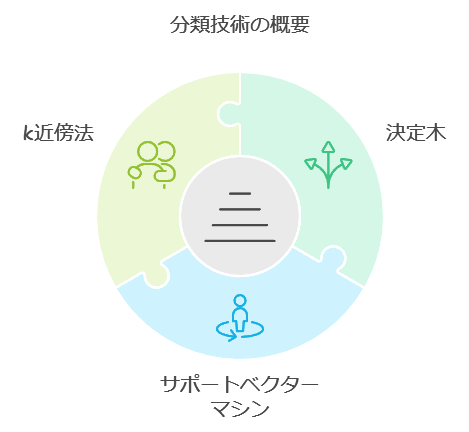
- 決定木:データを条件で分割していく手法で、直感的に理解しやすいのが特徴です。
- サポートベクターマシン(SVM):分類境界を決定する手法で、高次元データでも効果的です。
- k近傍法(k-Nearest Neighbors):新しいデータがどのクラスに属するか、近いサンプルに基づいて分類します。
3. 教師なし学習のアルゴリズム

クラスタリング
クラスタリングは、似たデータをグループ化する技術で、代表的な手法に以下があります。
- k-meansクラスタリング:データを「k」という数に分ける方法です。コンピューターはデータの真ん中(重心)を見つけ、その重心を中心にグループを繰り返し調整しながら作ります。
- 階層型クラスタリング:データの間の「距離」をもとに、データをまとめていきます。たとえば、似ているデータから小さなグループを作り、それをさらにまとめて「階層構造」のようにグループを作っていきます。
次元削減
次元削減は、データの特徴を簡素化しながらも情報を保つ手法で、以下が代表例です。
- 主成分分析(PCA):データの「ばらつき」を見て、重要な特徴を少ない数の軸にまとめます。データを「コンパクトに整理」しながらも、大事な情報はしっかり保てます。
- t-SNE:データの複雑な構造を「低次元」に視覚化する方法です。2Dや3Dにしてわかりやすく、たとえば「似ているデータが近くに集まる」ようにして見られるので、データのパターンがわかりやすくなります。
4. 強化学習の基礎
強化学習(Reinforcement Learning)は、エージェントが環境との相互作用から学習する手法で、「試行と失敗」を通じて最適な行動を見つけます。
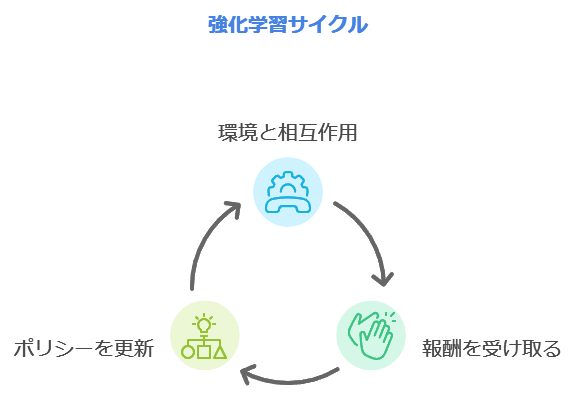
強化学習の重要概念
- エージェント:エージェントは、学ぶ「主体」のことです。ゲームで言えば「プレイヤー」、自動運転であれば「運転するAI」がエージェントです。このエージェントは「環境」の中で動き回りながら学びます。
- 報酬:エージェントが行動をしたときにもらえる「点数」のようなものです。正しい行動をすると高い報酬がもらえ、間違った行動をすると低い報酬や罰が与えられます。エージェントはこの報酬をたくさんもらえるように動き方を工夫していきます。
- ポリシー:エージェントがどう動くかを決める「戦略」のことです。ゲームで「得点が多くなるようにするにはどうすればいいか」を考えるように、ポリシーを通じてエージェントは自分の動きを決めていきます。
5. モデルの評価指標
評価指標の重要性
機械学習で「モデルがどれくらい正確か」を測るためには、正確な指標が必要です。これを使って、モデルの出来を確認し、改善が必要かどうか判断します。
分類問題の指標
分類問題は、あるデータが「猫か犬か」を判断するなど、カテゴリに分ける問題です。分類問題でよく使う指標には次のようなものがあります。
- 正解率(Accuracy):全てのデータの中で、正解したものの割合を表します。たとえば、「100個の問題中、90個正解した」なら、正解率は90%です。
- 精度(Precision):「正しいと判断したデータのうち、実際に正しかった割合」です。たとえば、「10個を正しいと判断したうち、8個が本当に正しかった」なら、精度は80%です。
- 再現率(Recall):「実際に正しいデータの中で、正しいと予測できた割合」を示します。たとえば、「20個が本当に正しいデータで、そのうち15個を正しく予測できた」なら、再現率は75%です。
- F1スコア:精度と再現率のバランスを取る指標です。精度と再現率の平均をとることで、どちらにも偏らない評価ができます。バランスよくモデルの評価ができます。
回帰問題の指標
回帰問題は、家の価格や気温など、数値を予測する問題です。回帰問題では以下の指標がよく使われます。
- 平均絶対誤差(MAE):予測値と本当の値の差を平均したもので、「誤差の平均」です。誤差が小さいほど、予測が実際の値に近いことを示します。
- 平均二乗誤差(MSE):誤差を二乗して平均したもので、大きな誤差に特に敏感です。予測が大きく外れたときにこの数値が大きくなります。数値が小さいほど、良い予測ができているといえます。
- 決定係数(R²):予測したモデルがデータのばらつきをどれだけ説明できているかを示します。1に近いほど、モデルがデータの特徴をよく捉えています。
次回予告
次回は、深層学習(Deep Learning)の基礎に入り、ニューラルネットワークの仕組みやアルゴリズムについて学びます。深層学習の基礎理解により、AIの高度な応用について理解を深めましょう。